Nov 21, 2025 - Toward self-directed RL for iterative model improvement
GRPO-style RL-post training is great, as Deepseek-R1 first showed. But there are some big obstacles, mainly due to data efficiency:
- As the model gets smarter, we need more and more difficult problems – this now requires expert human labeling. How to do this with synthetic data?
- Plain RL with GRPO has sparse reward – a long-horizon trajectory ends up with a single outcome (and maybe rubric-based) reward applied to all of the tokens generated. This is very data-inefficient.
- This can be solved with process-reward based supervision – i.e. give partial credit to different steps in a generated trajectory.
- This approach has lost some steam for a bit since Deepseek-R1 paper came out and indicated that they couldn't get this to work reliably.
- But it's becoming obvious that this can be done by using LLM-as-a-judge to avoid generating hand-crafted reference solutions.
But the first problem, the need to for ever more difficult prompts for the model to think about, is still a big obstacle with expensive current solution (pay SMEs to handwrite problems and solutions) and we can eventually hit some type of wall to obtain better training data/prompt!
AgentEvolver introduces a framework of self-questioning, self-navigating, and self-attribution within a verifiable environment/simulator as a comprehensive synthetic pipeline to perform RL.
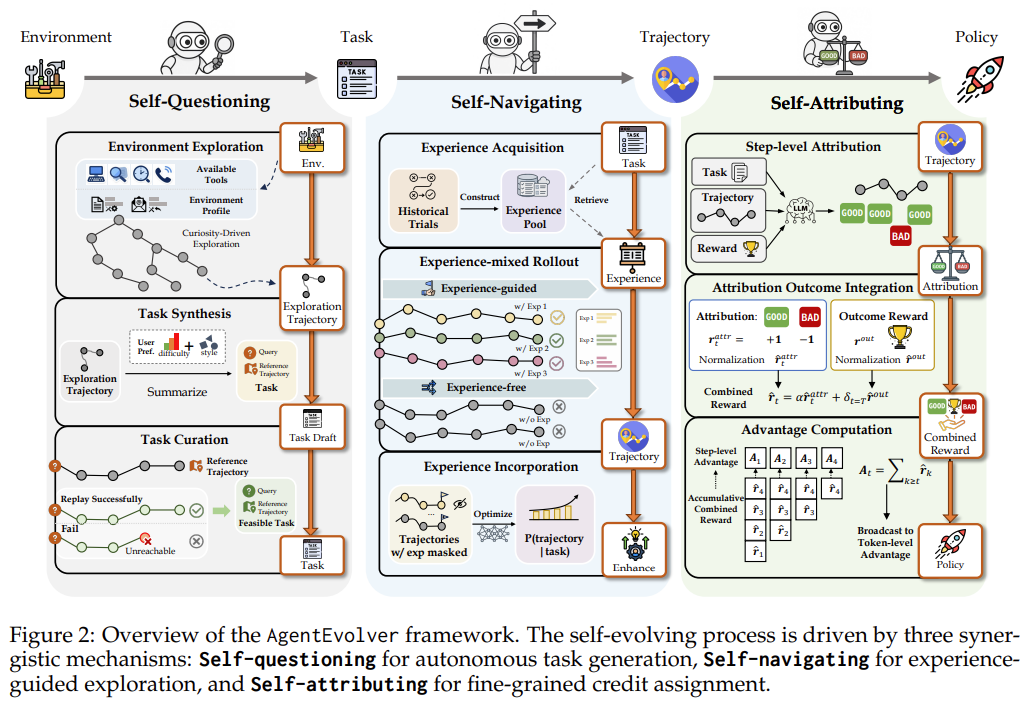
The rough setup:
- Given an unknown environment, defined with “attributes” and “actions”, the agent first explores different combinations of actions that can be performed on different attributes, and observes the outputs (e.g. “opening a file named x”, “pressing button y on window z”)
- This self-exploration phase helps compile a dataset of what’s “possible” in this environment, and maps out the “boundary” of this state-action space.
- The exploration is stochastic and reveals low-likelihood scenarios which might be difficult for a human labeler or LLM to enumerate.
- In the self-questioning phase, based on the trajectories compiled during exploration, the LLM can use this to infer potential “tasks’ that might result in such desired trajectories. This is synthetic task generation. Additionally, the trajectories from which the synthetic tasks are derived from thus yield reference trajectories, useful for process reward supervision later.
- Of course, different filtering based on user preferences keeps only tasks of certain difficulty and relevance.
- In the self-navigating phase, the agent conducts rollouts to solve these synthetic tasks, resulting in multiple trajectories per task.
- In self-attribution phase, process reward supervision via LLM judge (can be the model itself!) is performed on each trajectory rollout.
- For each step, i.e. a (context, action) pair, the LLM judge decides whether it contributed to the success or failure of the final outcome.
- In process-reward calculation, normalization is done first across each trajectory, before calculating the per-step mean/standard deviation for advantage calculation used for GRPO.
- The final reward calculation combines both process-reward and outcome reward for each step (and the tokens within each step).
- The policy is updated similar to GRPO-RL updates.
This setup is one more step toward the AlphaGo style self-play method. The self-question phase conducts search to generate synthetic tasks, which then leads to RL training that effectively teaches the policy model how to search and reason during inference. This setup is also similar to how Ramanujan discovered a bunch of mathematical results based purely on a fixed set of axioms and theorems. We can imagine having a mathematical environment (e.g. Lean) where the agent learns how to solve novel problems by finding application of specific math operations discovered during self-exploration (I think this is what axiom might be doing to train their model for math discovery).
The RL data problems are alleviated in this approach.
- We can replace data generation phase from “figure out scenarios and enumerate different trajectories according to rubric as data” to “building different environments of interest”
- As the model becomes better, the tasks it can generate from explored trajectories can become more diverse, and can act as a better process-supervision judge.
- One nagging question is, how does training the policy model in environment A helps with performance in a different environment?
- We know from current RL literature that the reasoning ability learned during even vanilla GRPO RL training transfer to other tasks (e.g. RLVR on math and coding tasks help with general reasoning with e.g. GPQA eval performance)
- The policy model can be updated from rollouts in different environments simultaneously (multi-task learning)
There are some other very cool tricks introduced that increase data-efficiency even more, and ablation studies reveal additional tricks that can improve convergence:
- Experience-guided navigation: From the initial trajectories derived from self-exploration, an LLM can summarize “experiences” (i.e. “when accessing a database, check for existing of key first”). Then during subsequent task solving, relevant experiences can be appended to the context (via RAG). Leveraging past experiences is equivalent to exploitation and helps with more efficient learning and better rollout success, and is especially beneficial during early training.
- For model updates, the “experiences” are stripped/masked from the context, and the advantage calculations for trajectories produced with experiences appended are relaxed (higher clipping level). The rationale is that without the experiences, the subsequent trajectories can be very unlikely, resulting in very large token prob ratio of the successful tokens – but we want the model to learn this, and increasing the clipping threshold ensures that.
- During a batch update, the ratio of trajectories WITH and WITHOUT experiences can be varied (i.e. the exploitation-exploration ratio). Varying this hyperparameter results can result in even better convergence.
- Attribution reward weighting: During training, assigning different weight to self-attribution reward vs. strict outcome reward can change convergence rate. Higher weight during earlier steps favor faster initial learning while lower weight during later steps increases final performance level.
The paper applied this framework to train different sized models within TWO tool-calling benchmarks (AppWorld and BFCLv3). These make easy testing environments. Notable results:
- Transfer learning: Training on one benchmark improves model performance for the other
- Synthetic data through self-questioning is effective:
- Increasing the amount of training data through synthetic data accounts for majority of the improved benchmark performance
- Using synthetic data alone for training results in model performance improvement similar to using human labeled dataset (<5% difference)
- Training on trajectories generated leveraging experience results in a significant improvement compared to vanilla RL baseline, but only if the clipping threshold is increased.
- Outcome reward accounts for most of the performance improvement compared to zero-shot performance, process reward via self-attribution also improves upon zero-shot performance on its own.
- Attribution reward improves data efficiency by 50%+
- Both model types (7B, and 14B) show similar trends, but the improvements are less for bigger models (probably not surprising).