
Bridging neuronal correlations and dimensionality reduction
Pairwise correlations between individual neurons, and dimensionality reduction based methods to characterize population statistics are widely used to measure how neural populations covary. This paper establishes mathematical relationships between the two approaches and demonstrate that summarizing population-wide covariability using any single activity statistic is insufficient.
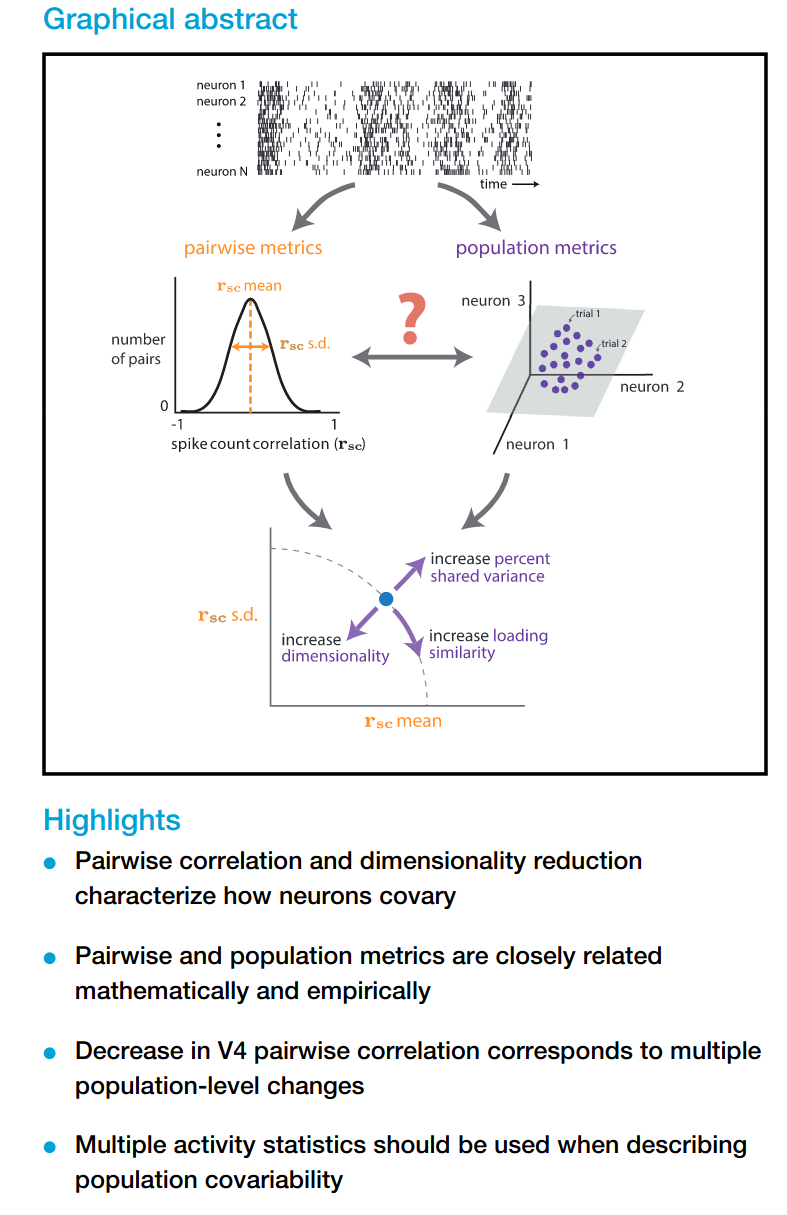
The graphical abstract and highlights on the publication are actually very informative after reading through some of the paper:
As is typical Byron Yu/Aaron Batista fashion, this paper presents a clever application of dimensonality reduction (specifically factor analysis).
Neuroscience literature often presents pairwise statistics to characterize neural populations (i.e. average spike-count correlations before and after learning BMI). They first propose that that this measure \(r_{sc}mean\) needs to be complemented by the pairwise metric standard-deviation \(r_{sc}SD\), then connect how the changes in this pair of pairwise metrics relate to population-level metrics obtained through dimensionality reduction.
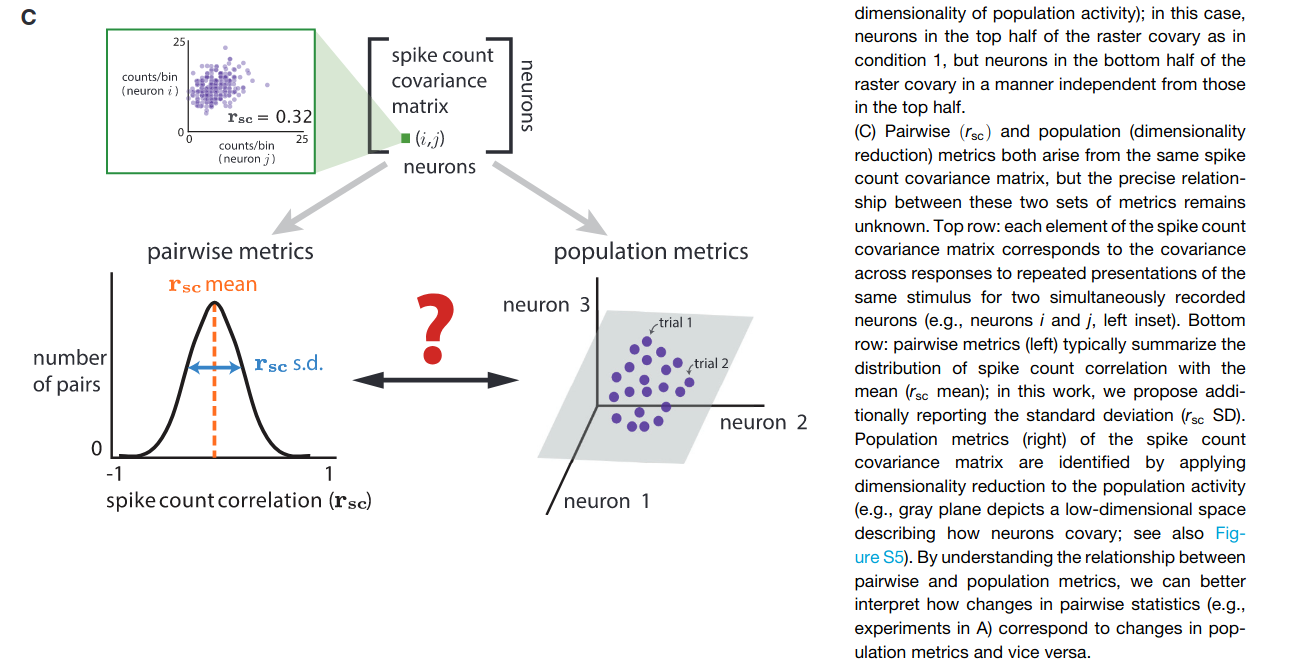
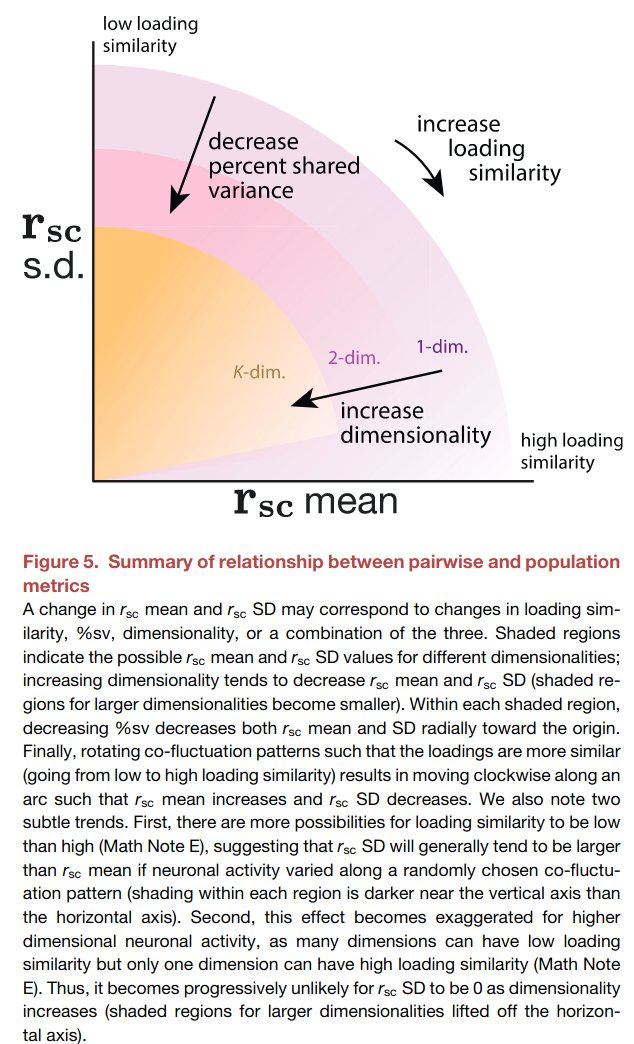
The next three figures illustrate the population-level metrics, and their relationship with pairwise metrics. The central idea is that the population activity can have different degree of covariation, which can be decomposed into shared variation along a number of latent fluctuations.
- Loading similarity: How correlated population activities are.
- Percent-shared variance: How much each neuron’s fluctuatons is captured by the latent co-fluctuation.
- Dimensionality: The number of “co-fluctations” needed to capture the variance in the population activities (similar to number of PCs in PCA).
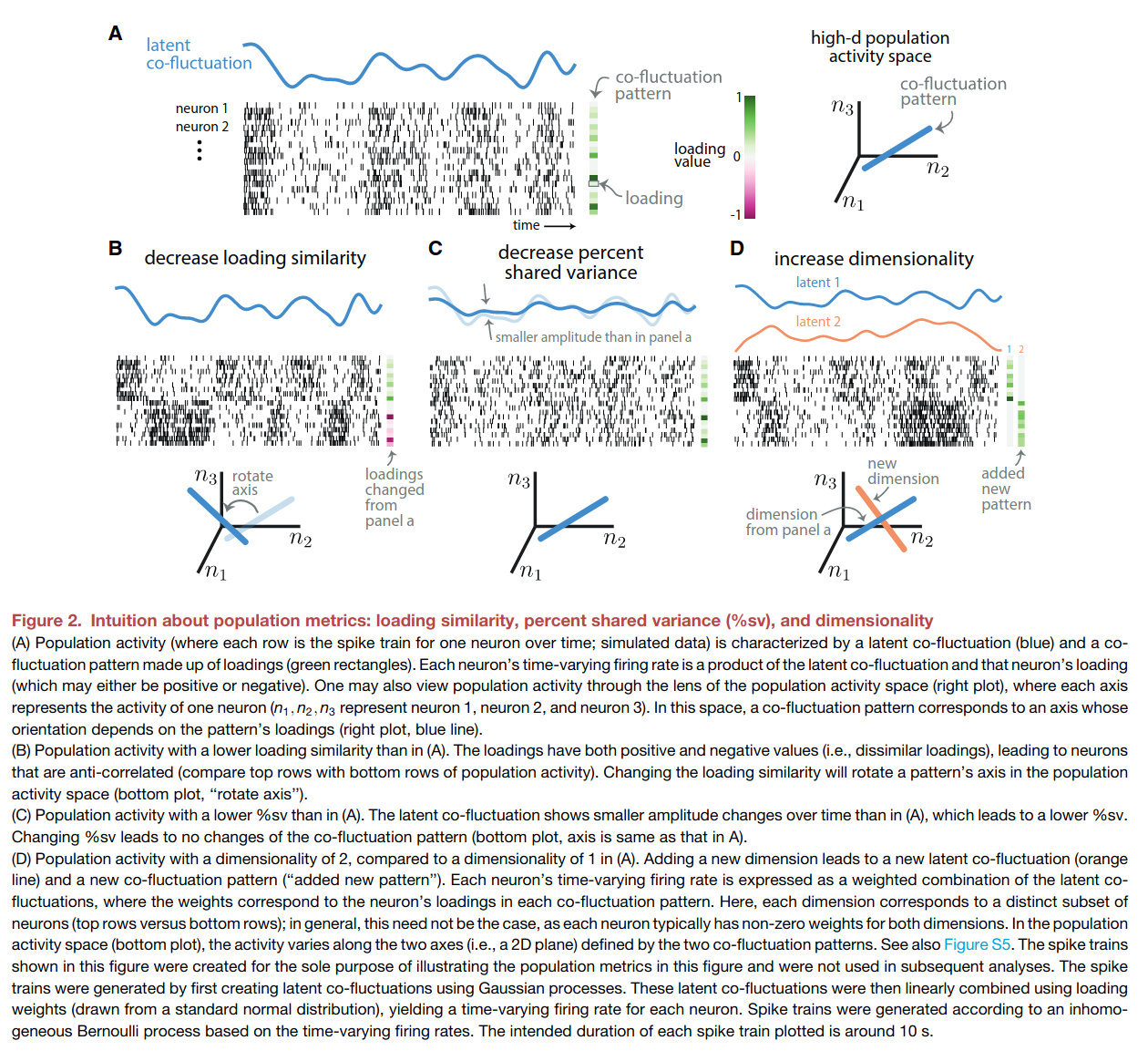
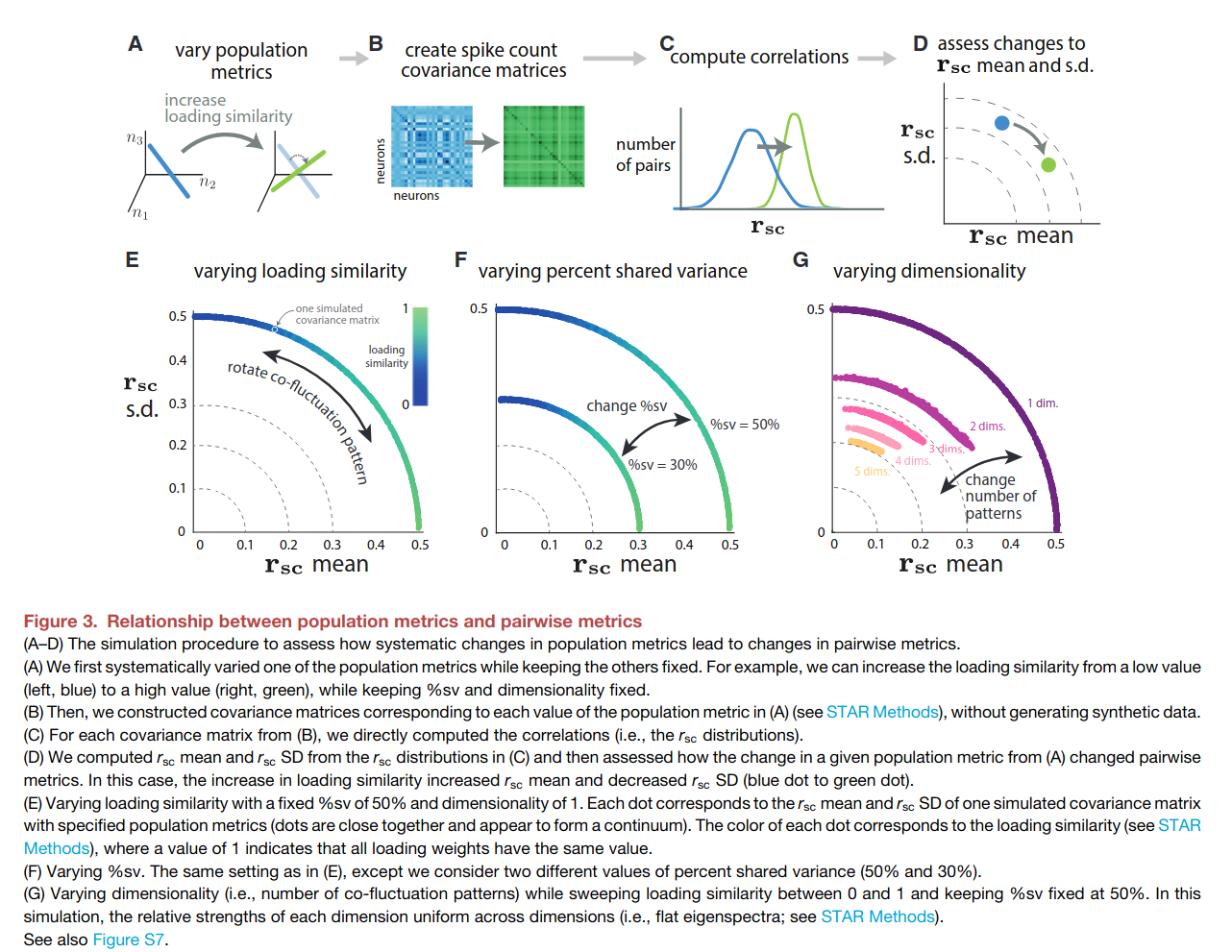
If all these sounds like factor analysis (FA), that’s because it’s a different way of interpreting F.A. The crux of the paper below:



