
Coadaptive Brain-Machine Interface via Reinforcement Learning
This is one of the very first papers that uses a reinforcement learning (RL) framework for BMI decoding. The technique used is semi-supervised because only a scalar (in this case, binary) reward signal is provided after tasks. This is markedly different from the more traditional supervised learning (SL) approach to decoding that uses kinematic variables as desired signal to train a regression model, etc.
The authors claim that the RLBMI architecture involves two coupled systems - while the user learns to use the BMI controller through neural adaptation, the BMI controller learns to adapt to the user via RL. While in theory this sounds promising, not much neural data is presented to show the neural-adaptation aspect of the architecture.
Computational Architecture: Q-learning. To the controller, environment=User’s Brain, State=neural activity, actions=prosthetic movement, rewards=task complete.
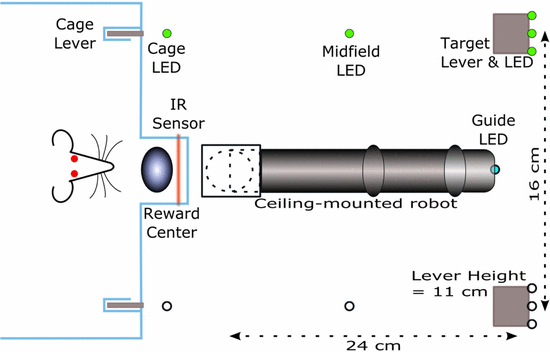
Experiment setup used
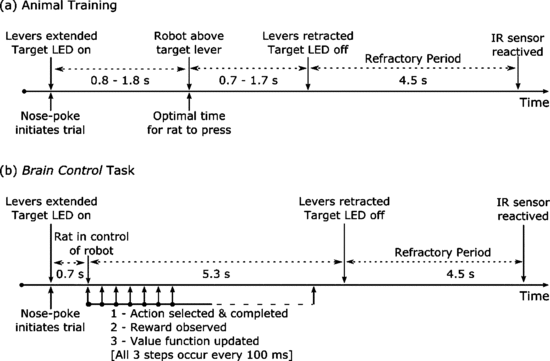
Experiment protocol
Goal is for the rat to move the robot arm to the other end of the room, to the lever that’s lit up. During brain-control, both the rat and controller will be rewarded when the arm is naeuvered proximal to the target. So distance to goal is used as a reward metric. This is intention-estimate, which is what the closed-loop decoder adaptation (CLDA) approaches Carmena’s group use.
In this RLBMI architecture, the value function estimation (VFE) is a non-trivial task. The value function Q is too big to be stored in a lookup-table, since while the total number of actions (robot movements) is 27, the number of possible states (neural vector configurations) is intractable. Thus a fully connected neural network is used, with a single layer of hidden units. Updated with *temporal difference (TD) error via backpropagation.
Weights were initialized to random. Goal for the BMI is some big radius within the goal. As training continued, the radius becomes smaller and smaller until it contains just the goal.
Neural data analysis shows rats were biased toward using a subset of the available robot actions, which moves the arm to target with not the most direct trajectories for all targets. Hidden layer feature representations should be analyzed to see how this happened, and how much of this is contributed by neural adapation vs. decoder adaptation.
Problems: RL-Deep learning is usually trained with large-batch of offline simulation data to speed up learning the value function. In the paper, the available data were reused in multiple-epoch, offline VFE training. Suggested using model-based RL that includes an environemental model to estimate future states and rewards…but this sounds just like Kalman filters with adaptive elements. Finally, rewards were prorammed by the BMI designer, but ideally they should be translated from the user’s brain activity – either the cortex or maybe basal ganglia.
Image cited: DiGiovanna, J.; Mahmoudi, B.; Fortes, J.; Principe, J.C.; Sanchez, J.C., “Coadaptive Brain–Machine Interface via Reinforcement Learning,” Biomedical Engineering, IEEE Transactions on , vol.56, no.1, pp.54,64, Jan. 2009. doi: 10.1109/TBME.2008.926699
References to Read
- R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction, 1998, MIT Press
- J. K. Chapin , K. A. Moxon , R. S. Markowitz and M. Nicolelis, “Real-time control of a robot arm using simultaneously recorded neurons in the motor cortex”, Nat. Neurosci., vol. 2, pp. 664-670, 1999