
This paper advances the SOTA on silent-speech decoding from EMG recorded on the face. “Silent” here means “vocalized” or “mimed” speech. The dataset comes from Gaddy 2022.
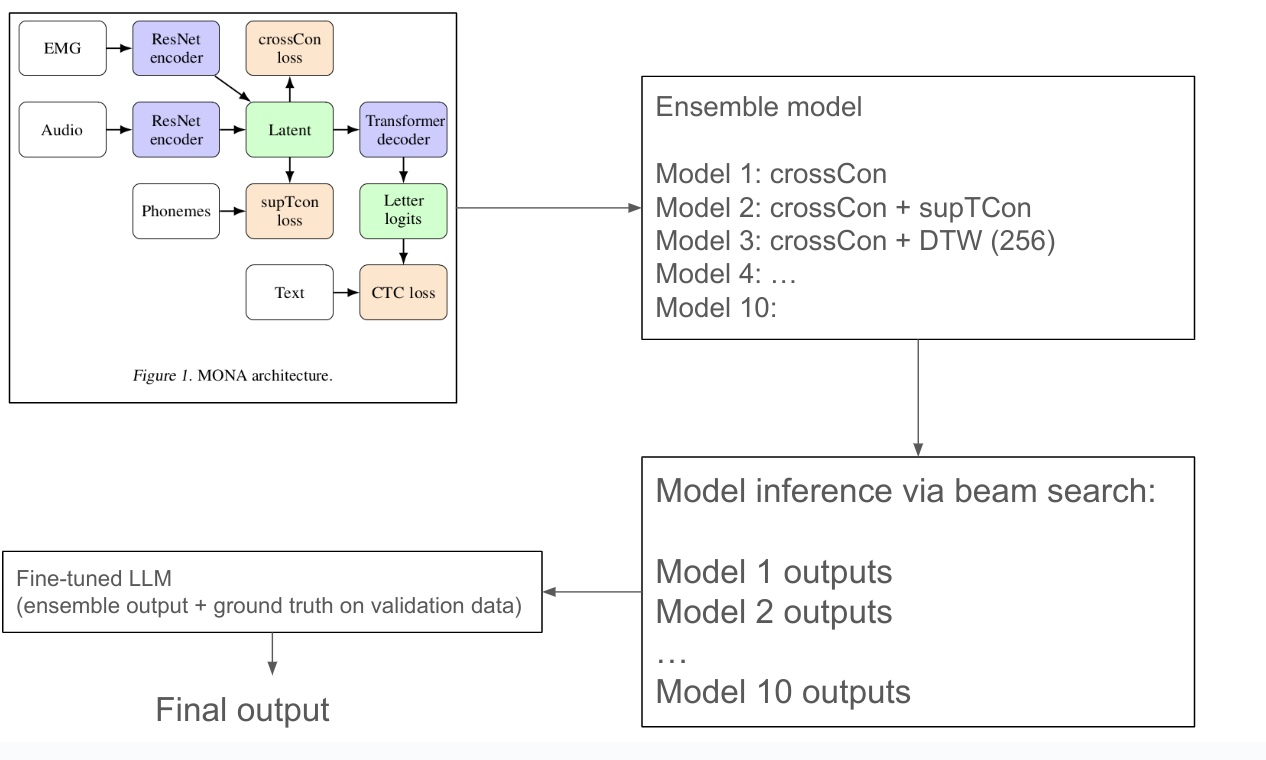
Image above shows the overall flow of the work:
- Model is trained to align EMG (from vocalized and silent) and audio into a shared latent space from which text-decoding can be trained. This training utilizes some new technique they call “cross-modal contrastive loss” (crossCon) and “supervised temporal contrastive loss” (supTCon). More on this later.
- They take the 10 best models trained with different loss and data-set settings, and make into an ensemble.
- For inference, they get the decoded beam-search output from these different models, and pass them into a fine-tuned LLM, to infer the best text transcription. They call this LLM-based decoding “LLM Integrated Scoring Adjustment” (LISA).
Datasets
The Gaddy 2022 dataset contains:
- EMG, Audio, and Text recorded simulataneously during vocalized speech
- EMG and Text for silent speech
- Librispeech: Synchronized Audio + Text
Techniques
A key challenge to decode silent speech from EMG is the lack of labeled data. So a variety of techniques are used to overcome this, drawing inspiration from self-supervised learning techniques that have advanced automatic-speech recognition (ASR) recently.
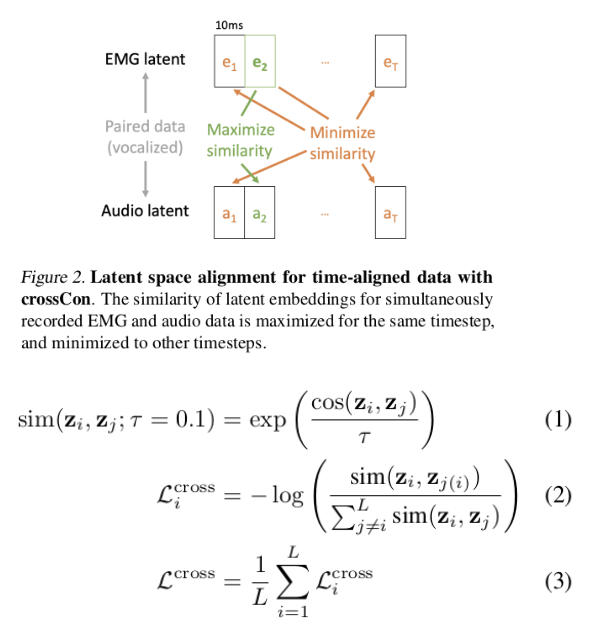
Cross-modality Contrastive Loss (crossCon): Aims to make cross-modality embeddings at the same time point more similar than all other pairs. This is really the same as CLIP-style loss.
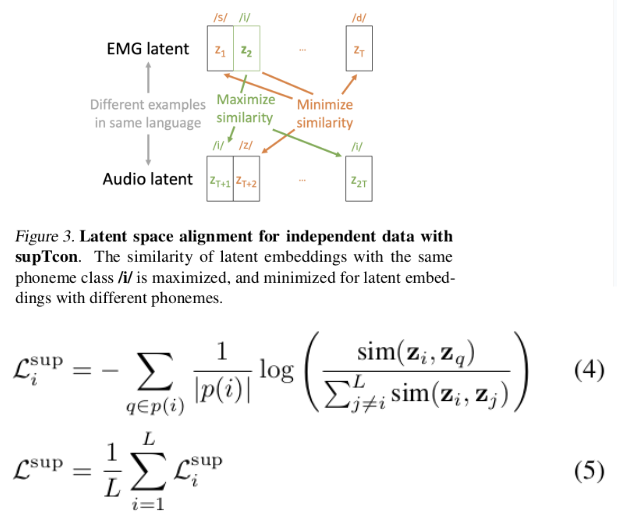
Supervised temporal contrastive Loss (supTCon): This loss aims to leverage un-synchronized temporal data by maximizing similarity between data at time points with the same label than other pairs.
Dynamic time warping (DTW): To apply crossCon and supTCon to silent speech and audio data, it’s important to have labels for the silent speech EMG. DTW leverages the fact that vocalized EMG and audio are synchronized, by:
- Use DTW to align vocalized and silent EMG
- Pair the aligned silent EMG with the vocalized audio embeddings.
Using audio-text data: To further increase the amount of training data, Librispeech is used. Since the final output is text, this results in more training data for the audio encoder, as well as the joint-embedding-to-text path.
All these tricks together maximize the amount of training data available for the models. I think there are some implicity assumptions here:
- EMG and Audio have more similarity with EMG and Text, since both Audio and EMG have temporal relationship.
The use of a joint-embedding space between EMG and Audio is crucial, as it allows for different ways to utilize available data.
LISA: An LLM (GPT3.5 or GPT4) are fine-tuned on the EMG/Audio-to-Text outputs for the ensemble models, and the ground truth text transcriptions. This is done from the validation dataset. Using LLM to output the final text transcription (given engineered prompt and beam-search paths), instead of the typical beam-search method, yielded significant improvements. And this technique can replace other language-model based speech-decoding (e.g. on invasive speech-decoder output) as well!
Details:
- CrossCon + DTW performed the best. It’s interesting to note that DTW with longer time-steps (10ms per timepoint) perform better.
- SupTCon loss didn’t actually help.
- Mini-batch balancing: Each minibatch has at least one Gaddy-silent sample. Vocalized Gaddy samples are class-balanced with Gaddy-silent sample. The rest of the mini-batch is sub-sampled from Librispeech. This is important to ensure the different encoders are jointly optimized.
- GeLU is used instead of ReLU for improved numerical stability.
- The final loss function equals to weighted sum EMG-CTC_loss, Audio-CTC_loss, CrossCon and supTConLoss
Final Results on Word-Error Rate (WER)
For final MONA LISA performance (joint-model + LLM output):
- SOTA on Gaddy silent speech: 28.8% to 12.2%
- SOTA on vocal EMG speech: 23.3% to 3.7%
- SOTA on Brain-to-Text: 9.8% to 8.9%
Additional userful reference
Cites Acceptability of Speech and Silent Speech Input Methods in Private and Public:
The performance threshold for SSIs to become a viable alternative to existing automatic speech recognition (ASR) systems is approximately 15% WER